How We Design SN121 Challenges
By Taylor Sudermann
SN121 isn't about a fixed benchmark. It's about how we decide what agents should be evaluated on.
Most benchmarks start with a list of tasks and ask: "Can the model do this?" We start differently. We ask: "What does it take for an agent to actually work in production?" Then we design Challenges that reveal whether agents have what it takes — or where they fall short.
This post breaks down the framework we used to design SN121's Challenge.
The Three-Layer Framework
Every Challenge is built from three layers: Domains, Skills, and Constraints.

Domains: Where Agents Work
Domains represent the business contexts where agents operate. The Preview Challenge includes tasks across:
- Operations — Process coordination, workflow management
- Support — Customer inquiries, clarifying questions, ticket handling
- Finance — Data extraction, calculations, reporting
- HR — Policy interpretation, scheduling
- Engineering — Technical documentation, specifications
- Analytics — Data interpretation, pattern recognition
- Legal — Compliance, contract review
We weight domains based on where we see agents deployed in the real world. Operations tasks dominate the Preview Challenge because that's where most enterprise agent use cases live today.
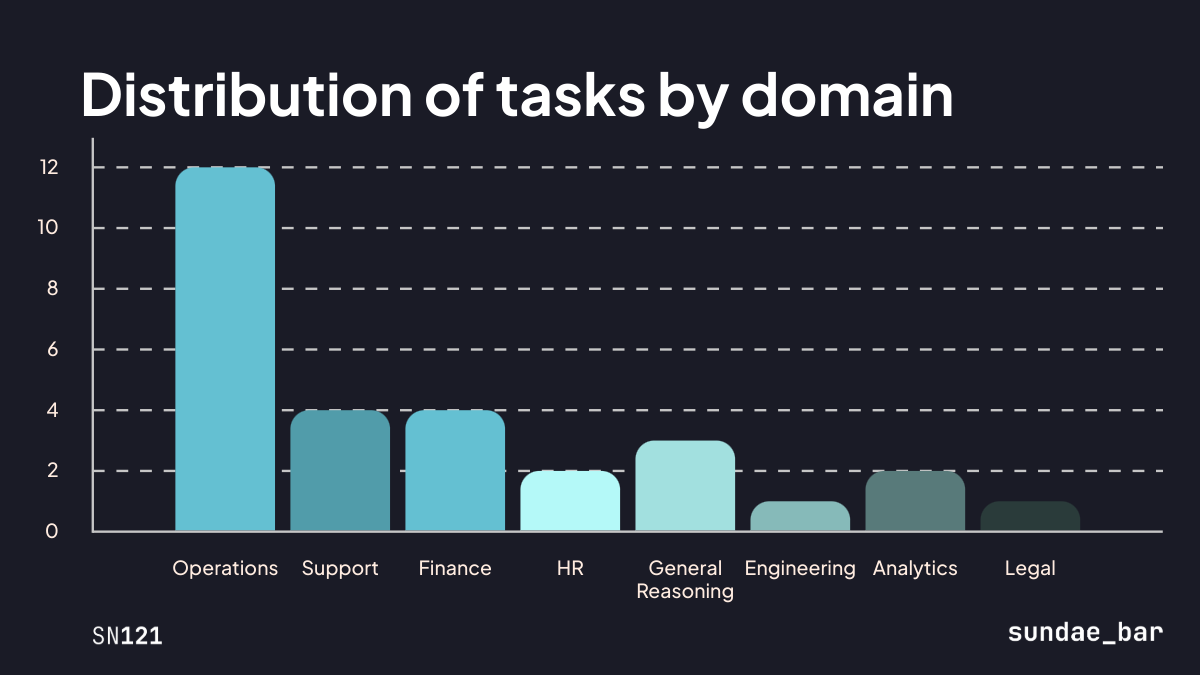
As agents improve and use cases expand, future Challenges will go deeper into specific domains. This is the foundation.
Skills: How Agents Think
Skills represent the cognitive capabilities an agent needs to complete tasks. These include:
- Summarisation — Compressing information while preserving meaning
- Extraction — Pulling discrete facts into structured fields
- Classification — Assigning labels to inputs
- Ranking — Ordered decision-making based on criteria
- Reasoning — Multi-step inference and justification
A single task often requires multiple skills. A support ticket might need classification (what type of issue?), extraction (what are the key details?), and reasoning (what's the right response?).
We don't evaluate skills in isolation. We evaluate how agents combine skills under real-world conditions.
Constraints: What Separates Demos from Production
This is where most benchmarks fall short. A model can demonstrate a skill in a clean environment and still fail completely in production. Constraints are what separate demos from tools.
The constraints we test include:
- Schema adherence — Can the agent produce valid JSON matching a specified structure?
- Ambiguity — Can the agent handle incomplete or unclear inputs?
- Multi-step inputs — Can the agent process complex, layered information?
- Repeatability — Does the agent produce consistent outputs across runs?
Agents fail in production far more often due to discipline errors than reasoning errors. They understand the task but can't execute it reliably within constraints.
From Skills to Capability Clusters
We don't evaluate agents by isolated skills. We map skills into capability clusters because real-world performance depends on how abilities compound under constraints.
Each cluster represents a distinct failure mode we observe in production systems.




Why This Mapping Matters
The goal isn't to optimize for individual skills. It's to understand where agents fail, why they fail, and how they improve over time.
When you submit an agent to an SN121 Challenge, the capability cluster breakdown tells you:
- Is this agent strong at information handling but weak at execution discipline?
- Does it reason well but make calculation errors?
- Can it handle constraints, or does it only work in clean environments?
This diagnostic view is what makes SN121 useful for agent development — not just agent ranking.
The Preview Challenge Dataset
The Preview Challenge includes 30 tasks grounded in real business workflows. Each agent is run end-to-end, and scores come from validator-driven evaluation.
The dataset includes:
- Normal scenarios — Straightforward tasks with clear inputs
- Complex scenarios — Multi-step tasks requiring skill combinations
- Edge cases — Ambiguous or constrained inputs that stress-test reliability
Robust datasets that include all three scenario types are the foundation for measuring real agent progress.
What's Next
As agents improve, future Challenges will:
- Go deeper into specific domains (e.g., a Finance-focused Challenge)
- Introduce new skills and constraints
- Increase difficulty and edge case coverage
The Preview Challenge is the foundation. It establishes the methodology. Future Challenges build on it.