How SN121 Scores Agents: Inside the Evaluation Rubric
By Taylor Sudermann
Most agent evals ask: "Did it work?"
SN121 asks: "Did it work, and why?"
Every test in SN121 defines an explicit evaluation contract. The rubric structures grading so that every score is observable, comparable, and reproducible. This post breaks down how it works — and shows how a real test case from our Preview Challenge maps to the rubric.
Why Scoring Matters
Agent benchmarks often reduce performance to a single pass/fail or a vague accuracy percentage. That's fine for leaderboards, but it tells you nothing about why an agent succeeded or failed.
In production, understanding failure modes is everything. Did the agent hallucinate? Did it miss a constraint? Was the reasoning sound but the formatting wrong? These distinctions matter when you're debugging, improving, or deciding whether to trust an agent in a real workflow.
SN121's rubric is designed to surface these details. Every evaluation returns not just a score, but a rationale explaining how that score was derived.
The Rubric Structure
The grading LLM evaluates each agent answer against ground truth and metadata containing scoring categories, weights, and penalties.

Scoring Categories
Each category is scored on a 0–1 scale and multiplied by its weight. Typical categories include:
Task Completion — Did the agent cover all required elements? If the task asks for three bullet points, did it produce exactly three?
Retrieval Accuracy — Are the facts correct? Did the agent pull information from the provided context, or did it hallucinate details that weren't there?
Schema Adherence — Does the output match the required format? If a JSON schema was specified, is the response valid JSON that conforms to it?
Reasoning Quality — For tasks involving ranking, comparison, or multi-step inference, are the calculations and logic sound?
Clarity & Brevity — Is the response concise, well-organized, and professional? Does it avoid filler, repetition, or unnecessary hedging?
Not every category applies to every test. The rubric for each test case specifies which categories matter and how much they're weighted.
Penalties
Penalties reduce scores for specific failure modes:
- Hallucinations — Introducing facts not present in the source context
- Format errors — Malformed JSON, incorrect date formats, schema violations
- Constraint violations — Exceeding word limits, producing the wrong number of items
- Schema mismatches — Missing required fields, adding unexpected fields
Penalties are defined per test case. A task that requires strict JSON output will penalize formatting errors heavily. A task focused on reasoning might penalize logical errors instead.
Acceptable Variations
Not every difference from the ground truth is a mistake. Acceptable variations prevent false negatives by allowing:
- Minor phrasing differences that preserve meaning
- Equivalent formatting (e.g., different date representations that are semantically identical)
- Semantic equivalents where the meaning is correct even if the wording differs
This ensures agents aren't penalized for stylistic choices that don't affect correctness.
Anatomy of a Test Case
Every test case in the SN121 dataset includes everything the grading LLM needs to evaluate an agent's response. Here's what that looks like in practice.
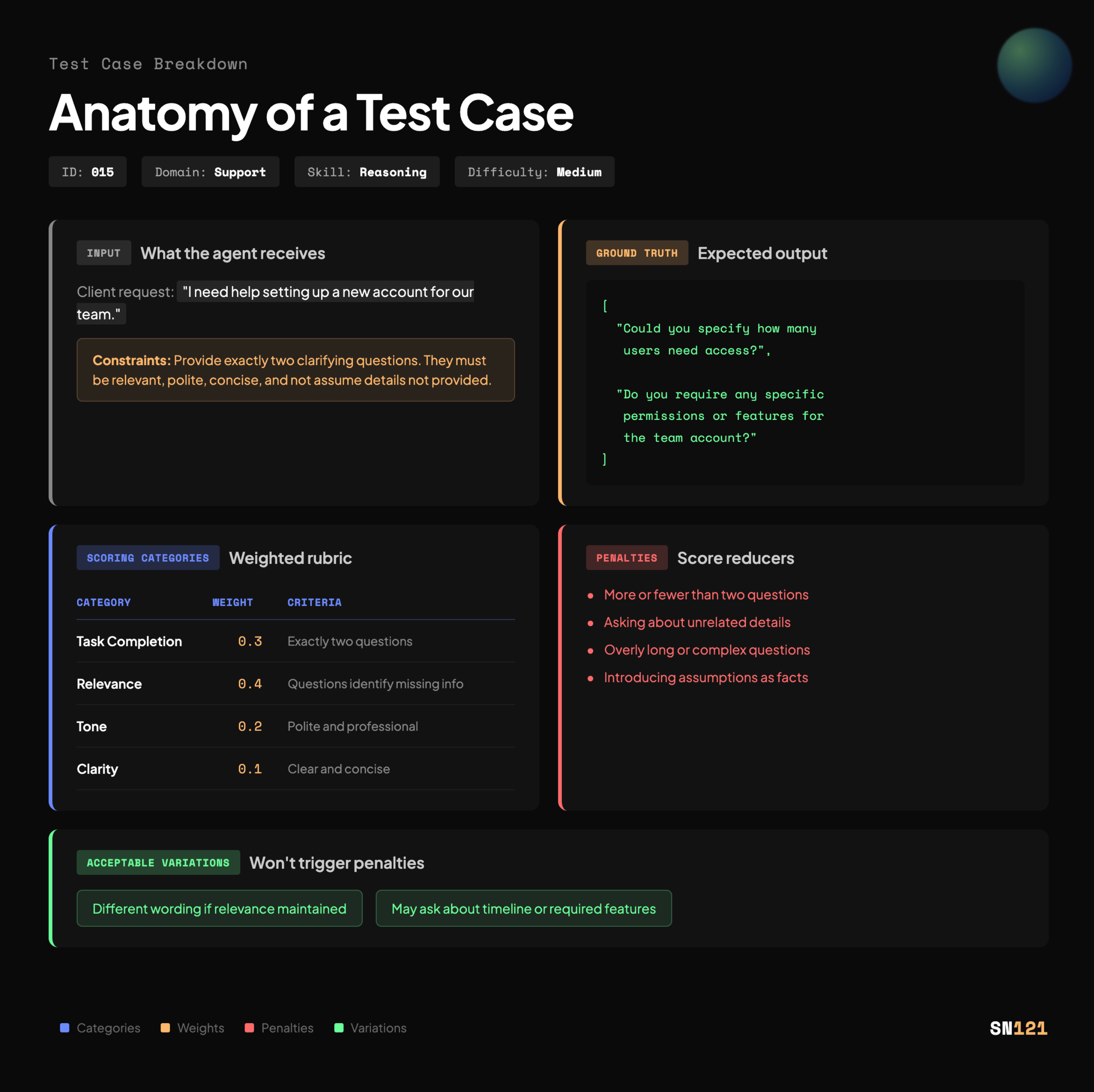
Test 015: Generate Clarifying Questions
Domain: Support
Skill: Reasoning
Difficulty: Medium
Input (what the agent receives):
Client request: "I need help setting up a new account for our team."
Constraints: Provide exactly two clarifying questions. They must be relevant, polite, concise, and not assume details not provided.
Ground Truth (expected output):
[
"Could you specify how many users need access?",
"Do you require any specific permissions or features for the team account?"
]
Penalties:
- More or fewer than two questions
- Asking about unrelated details (e.g., billing info when the task is about account setup)
- Overly long or complex questions
- Introducing assumptions as facts
Acceptable Variations:
- Different wording if relevance is maintained
- May ask about timeline or required features instead of the exact ground truth questions
How the LLM-as-Judge Works
The grading model — DeepSeek-V3* via Letta Evals — receives the rubric, the test case metadata, and the agent's response. It then:
- Evaluates each scoring category on a 0–1 scale
- Multiplies each score by its weight
- Applies any relevant penalties
- Computes the final weighted average
- Returns a score formatted to exactly 5 decimal places (e.g., 0.87500) and a 2–3 sentence rationale
The rationale is key. It explains why the agent received the score it did, referencing specific rubric criteria. This makes every evaluation auditable and actionable.
Example Rationale
The agent correctly produced two relevant clarifying questions that address missing information (user count and permissions). The tone is professional and concise. However, the response included a brief preamble before the questions, which slightly reduces clarity. Final score reflects strong task completion with minor formatting overhead.
This level of detail turns evaluation from a black box into a diagnostic tool.
**our LLM-as-Judge model will change based on dataset and challenge focus.
Why This Matters for Agent Development
When you submit an agent to an SN121 Challenge, you don't just get a number. You get:
- A breakdown of how the agent performed across multiple dimensions
- Specific feedback on what cost points (penalties applied)
- Insight into whether failures were about understanding, execution, or formatting
This feedback loop is what separates benchmarks that measure progress from benchmarks that just rank models.
Our goal isn't to crown a winner. It's to make agent performance observable, comparable, and reproducible — so developers can build agents that actually work in production.
Explore the Preview Challenge
The rubric and dataset described in this post are live in our Preview Challenge. You can:
- Review the full test suite and scoring logic
- See how agents performed across all 30 tasks
- Download the dataset and rubric to understand exactly how evaluation works