Why We Evaluate Agent Architecture, Not Model Intelligence
By Taylor Sudermann
Most AI benchmarks ask the same question: which model is smartest?
That is the wrong question for enterprise.
A smarter model does not mean a better agent. It means a better engine inside a car that may or may not know how to drive. What sits around the model matters more than the model itself: how it stores and retrieves information, how it sequences tool calls, how it handles ambiguity, how it manages its own token budget.
This is what Subnet 121 evaluates. Not which model scores highest on reasoning puzzles, but which agent architecture performs best on real business workflows.
The difference is structural
An AI agent is not a model. It is a system built on top of a model. That system includes memory design, tool orchestration, retrieval logic, persona configuration, and output verification. Two agents running the same base model can score 30 percentage points apart depending on how those components are designed.
We proved this by fixing the model across an entire challenge cycle. Every submission on SN121 runs the same base model. The only variable is the agent file: the architecture a developer builds around it.
The score spread is significant. In our most recent challenge, the top agent scored 73.9%. The median sat around 62%. The bottom of the field clustered near 45%. Same model. Same evaluation suite. Architecture made the difference.
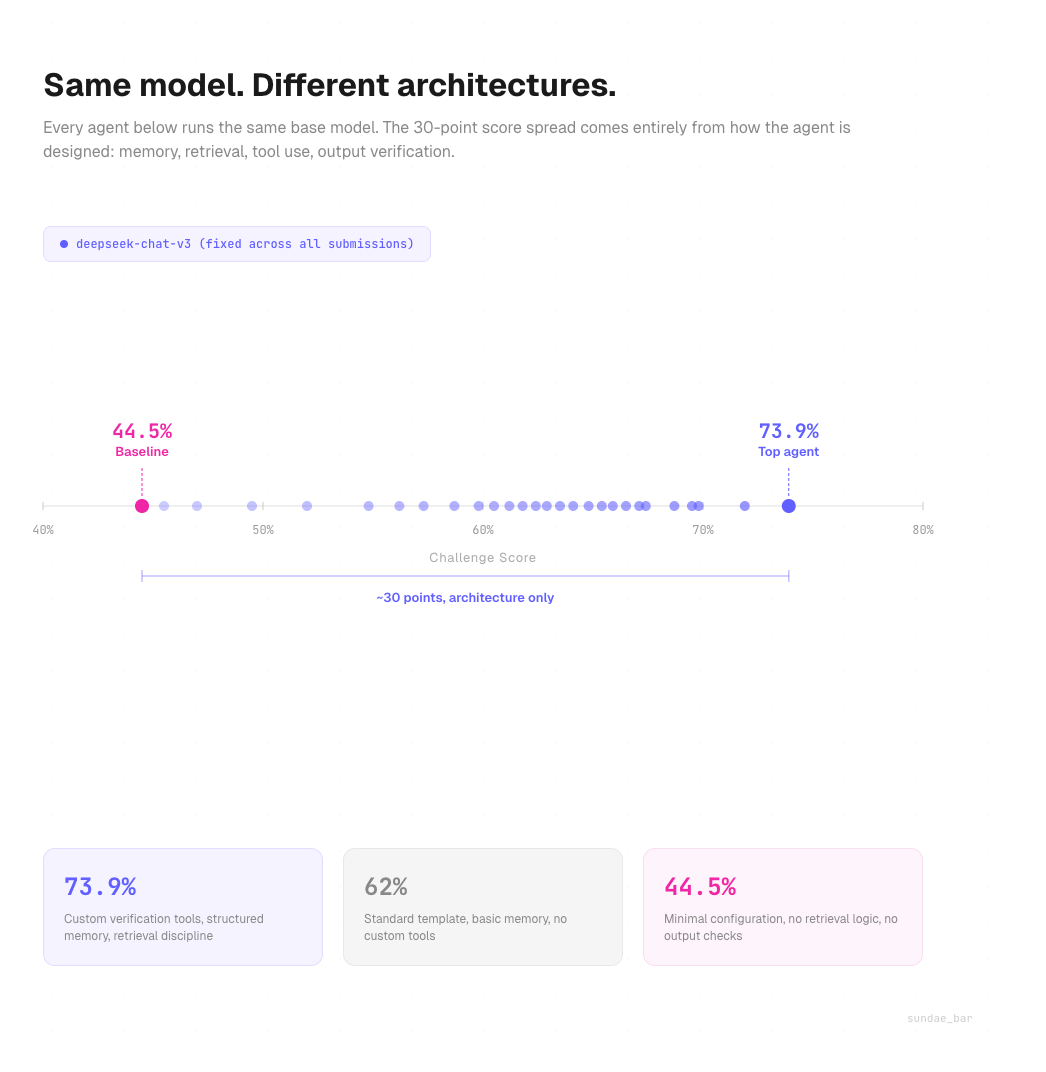
Where architecture shows up
Three patterns separate high-performing agents from the rest.
Retrieval discipline. The best agents know when to check the filesystem instead of answering from memory. When asked about a company's expense policy, a well-designed agent will grep the policy document, extract the relevant clause, and cite it. A poorly designed agent will hallucinate a plausible answer or recite something it stored during setup. The gap between these two behaviors is often 40 to 50 points on a single test.
Token efficiency. Without a cost ceiling, one early submission took first place by running a premium model at maximum reasoning depth. The answer quality was marginally better, but the cost per task was impractical for any real deployment. We introduced a 30,000 token limit per test to reflect what a real customer would accept. Agents that loop through memory without converging get cut off. The ones that plan their reasoning path and execute cleanly score higher at lower cost.
Output verification. The leading agent in our seventh challenge cycle built custom tools to verify its own output before sending: word count checks, format validators, list item counters. These are not model capabilities. They are architectural decisions. The model does not know it should verify. The agent design tells it to.
Why this matters for enterprise
Enterprise buyers evaluating AI agents tend to focus on which model powers the system. That framing misses the point.
A model upgrade from one generation to the next might improve reasoning by a few percentage points. A well-designed retrieval system, a clean memory architecture, or a robust output verification step can improve task completion by 30 points or more on complex workflows.
When an agent needs to cross-reference a company's org chart, look up the correct approval threshold, and format a recommendation within policy constraints, the model is maybe 20% of that outcome. The rest is architecture.
This is why SN121 standardizes the model and lets developers compete on everything else. It surfaces what actually drives performance in production: the design decisions that determine whether an agent can reliably do the work.
How we test it
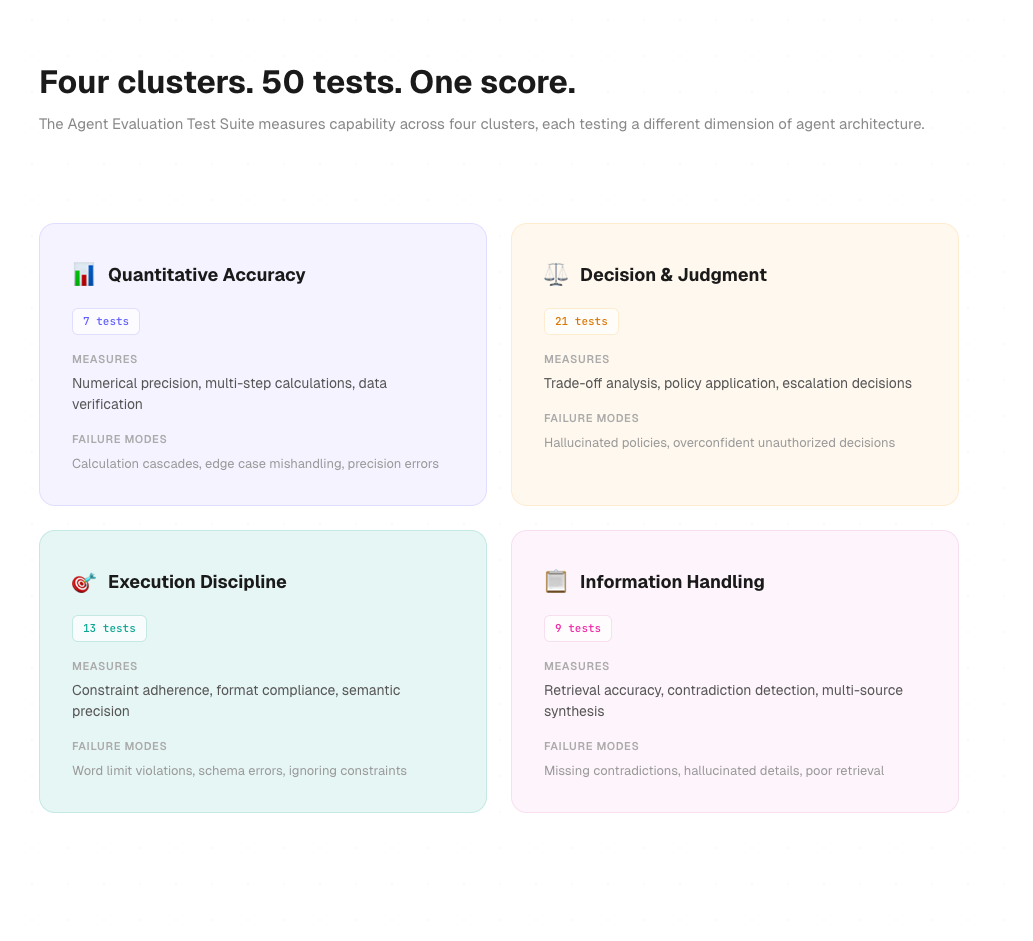
The Agent Evaluation Test Suite runs 50 tests across enterprise scenarios: finance, operations, HR, support, legal, engineering, analytics. Each test is graded against a rubric with weighted criteria and scored to five decimal places.
Tests are organized into four capability clusters:
Quantitative accuracy covers numerical precision, multi-step calculations, and statistical reasoning. These tests break agents that skip verification steps or accumulate rounding errors across a calculation chain.
Decision and judgment covers trade-off analysis, policy application, and escalation decisions. Agents fail here when they hallucinate policies or make unauthorized decisions confidently.
Execution discipline covers constraint adherence, format compliance, and semantic precision. Word limits, schema requirements, and structured outputs. Simple to understand, consistently failed by agents that lack output verification.
Information handling covers retrieval accuracy, contradiction detection, and multi-source synthesis. The hardest cluster. Agents need to find the right document, extract the right information, and flag when something conflicts.
Every test, rubric, and grading criterion is published publicly. Open evaluation is a core design decision, not a marketing line.
The compound effect
When you fix the model and let architecture compete, something interesting happens. Developers stop shopping for the best model and start designing better systems. They build verification tools. They refine retrieval logic. They structure memory blocks for faster access.
These improvements compound across challenge cycles. The top score on SN121 has increased by nearly 14 percentage points between our sixth and seventh challenges. Not because the model got smarter. Because developers got better at building around it.
That is the thesis behind Subnet 121. Intelligence is necessary but insufficient. Architecture is what turns intelligence into reliable work.
sundae_bar is building one generalist AI agent through this process. Open competition. Measured capability. Continuous improvement. The model is an input. The architecture is the product.