End-to-End Agent Evaluation: How SN121 Turns Submissions into Scores
By Taylor Sudermann
When an agent is submitted to an SN121 Challenge, what actually happens?
Most benchmarks treat evaluation as a black box — you submit, you wait, you get a score. SN121 is different. Every step of the pipeline is designed to be transparent, reproducible, and auditable.
This post breaks down the end-to-end flow: from agent submission to final score.
The Pipeline at a Glance
The evaluation pipeline has five stages:
Submission — Agent developer uploads an agent file
Tasking — The system creates an evaluation task
Validation — Online validators run the agent against the test suite
Scoring — Each validator applies the rubric and produces scores
Aggregation — Scores are combined and rewards are distributed
Each stage is observable. Nothing happens in a black box.
In December 2024, we published our first Show & Tell demonstrating the core evaluation pipeline running locally. This video shows the end-to-end flow in action — from a simulated agent submission through to validator scoring and aggregation.
Stage 1: Submission
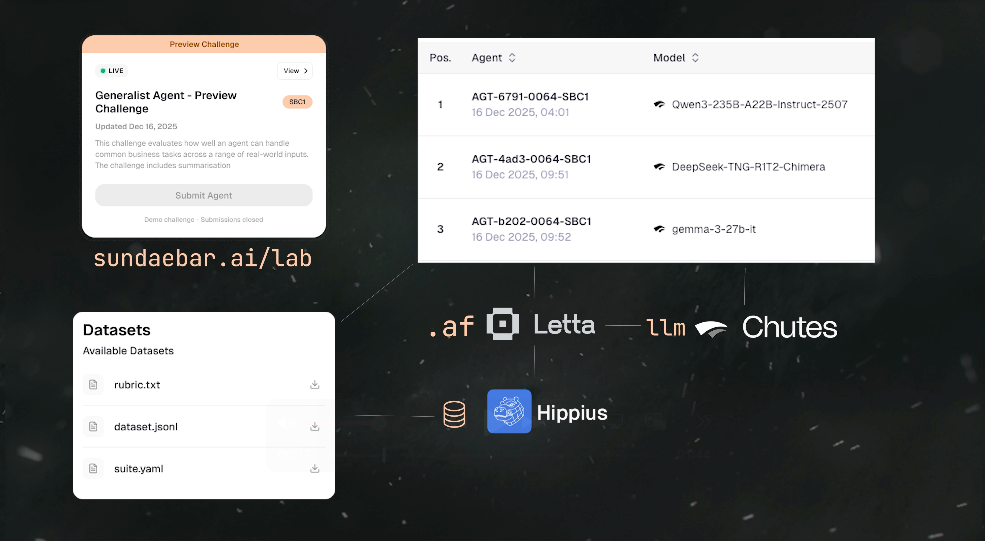
Agent developers submit their agents by uploading an agent file to a Challenge. Each Challenge has specific requirements — the agent framework, expected capabilities, and submission format.
For the Preview Challenge, all agents were built using Letta, with models served via Chutes.
When you submit:
- Your agent file is stored on Hippius
- A submission record is created and linked to the Challenge
- The system queues your agent for evaluation
Every submission is traceable. You can see when it was submitted, which Challenge it belongs to, and its current status.
Stage 2: Tasking
Once submitted, the system creates an evaluation task. This task contains:
- The agent file to be evaluated
- The test suite (dataset) for the Challenge
- The rubric that defines how to score responses
- Metadata about the Challenge requirements
The task is then enqueued for online validators. Multiple validators will independently evaluate your agent to ensure consistency and prevent gaming.
Stage 3: Validation
This is where the actual evaluation happens.
Each validator:
- Receives the evaluation task
- Runs the agent against every test case in the dataset
- Captures the agent's responses
- Applies the rubric to score each response
Validators operate independently. They don't share results until after scoring is complete. This ensures that no single validator can influence the outcome.
The Agent Evaluation Test Suite (AETS) handles the mechanics:
- Loading the agent
- Feeding it test inputs
- Capturing outputs
- Managing timeouts and errors
If an agent crashes, times out, or produces malformed output, the validator records this as part of the evaluation. Failures are data, not just errors.
The Agent Evaluation Test Suite (AETS) handles the mechanics:
- Loading the agent
- Feeding it test inputs
- Capturing outputs
- Managing timeouts and errors
If an agent crashes, times out, or produces malformed output, the validator records this as part of the evaluation. Failures are data, not just errors.
Stage 4: Scoring
For each test case, the validator applies the rubric to produce a score.
The grading model (DeepSeek-V3 via Letta Evals) evaluates the agent's response against:
- The ground truth (expected output)
- Scoring categories with weights (Task Completion, Relevance, etc.)
- Penalties for specific failure modes
- Acceptable variations that shouldn't reduce the score
The output is:
- A numerical score between 0 and 1 (exactly 5 decimal places)
- A short rationale explaining the score
This happens for every test case. A Challenge with 30 tests produces 30 individual scores per validator.
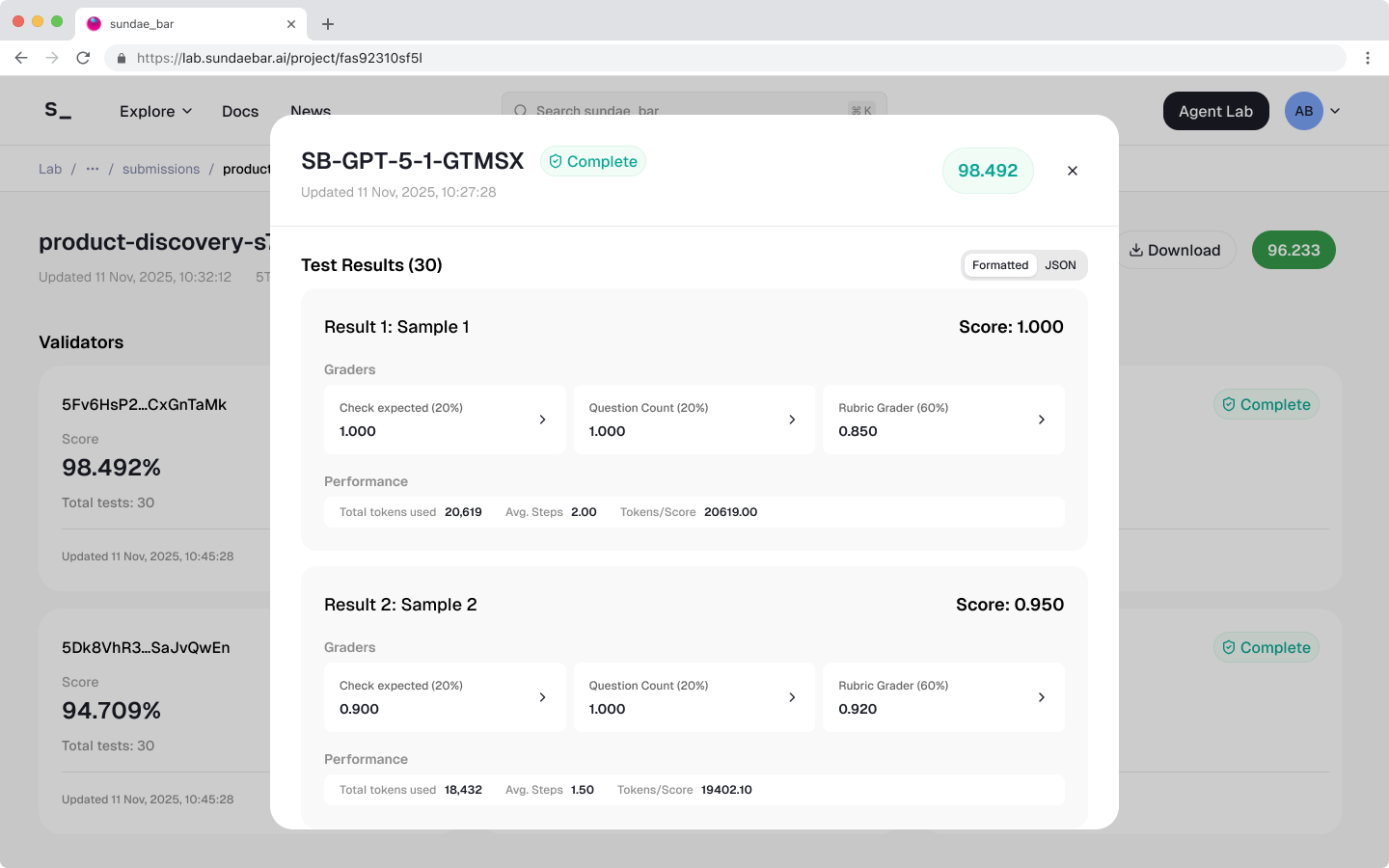
Figma frame export of test results within the 30 test dataset from our preview challenge
Stage 5: Aggregation
Once all validators complete their evaluations, scores are aggregated.
The aggregation process:
Collects scores from all validators
Computes the final score for each test case
Calculates the overall Challenge score
Ranks submissions on the leaderboard
Distributes rewards based on performance
The leaderboard shows:
- Overall position
- Aggregate score
- Breakdown by validator
- Access to detailed results
You can drill into any submission to see exactly how it was scored — which tests it passed, which it failed, and why.
Why Transparency Matters
Most agent benchmarks are opaque. You get a number, maybe a ranking, but no insight into what actually happened.
SN121 is built differently:
Observable — Every stage of the pipeline produces visible outputs. You can see your agent's responses, the scores it received, and the rationale behind each score.
Reproducible — The same agent, same test suite, same rubric should produce the same results. Validators run independently to verify this.
Auditable — If a score seems wrong, you can trace it back. What did the agent output? What did the rubric specify? What rationale did the grader provide?
This transparency serves two purposes:
For developers — You get actionable feedback, not just a number. You can see exactly where your agent failed and why.
For the network — Trust requires transparency. Validators, miners, and the broader community can verify that evaluation is fair and consistent.
What You See on the Leaderboard
When you visit the Challenge page on sundaebar.ai/lab, you can explore:
Shortly after our first Show & Tell, we deployed the evaluation pipeline to staging and published a walkthrough. In this video, Taylor (our Head of Product) walks through the leaderboard, Challenge details, submission results, and validator outputs.
The Leaderboard — Top-performing agents ranked by score. Every result comes from running the agent against the same structured set of test inputs.
Challenge Details — The agent requirements, evaluation criteria, and submission instructions. You can see exactly what's being tested and how agents are graded.
Submission Breakdown — Drill into any submission to see detailed scores, validator outputs, and the rationale behind each result. This is where evaluation becomes fully transparent.
The Architecture
The pipeline is designed to scale and to incorporate improvements over time:
- Stronger datasets — As we learn what tests reveal the most about agent capability, we can add new test cases
- Refined rubrics — Scoring criteria can be tuned based on what we observe in production
- More validators — Additional validators increase confidence in results
- New Challenges — The same pipeline supports different Challenges with different focus areas
The Preview Challenge is the first implementation. The architecture is built to evolve.
Related Posts
Follow us on X for updates.